

Artificial Intelligence startups raised more than $130 billion in 2024. Many hundreds of billions more were invested by the corporate and public sectors.
Then a Hangzhou, China-based generative AI startup backed with only a few million dollars called DeepSeek launched and dominated the competition.
What comes next?
Rapid Iteration and
Evolution
To find out where we’re going, we must first know how we got here.
Artificial Intelligence has a long history that goes back to the 1950s. However, a so-called “intelligence explosion” has only taken place in the past 7-10 years.
This is when the rapid iteration and evolution of algorithmic models, on the order of 5x computing gains in a single year, began.
From OpenAI’s ChatGPT to Anthropic’s Claude, the jump has put us on a path toward artificial general intelligence (AGI) by 2030 or sooner by some estimates.
AGI is when AI becomes capable of human reasoning and it was widely acknowledged and understood that it would be an expensive task, to put it mildly.
OpenAI CEO Sam Altman once told a group of Stanford students that he genuinely doesn’t care “whether we burn $500 million a year or $5 billion, or $50 billion a year. As long as we can figure out a way to pay the bills, we’re making AGI.“
This was before January 20th, 2025.
That’s the date DeepSeek’s ‘R1’ Large Language Model (LLM) was introduced and it changed everything.
Despite being founded less than two years ago with purportedly far less funding, the model has demonstrated performance comparable to OpenAI’s most sophisticated o1 series models:
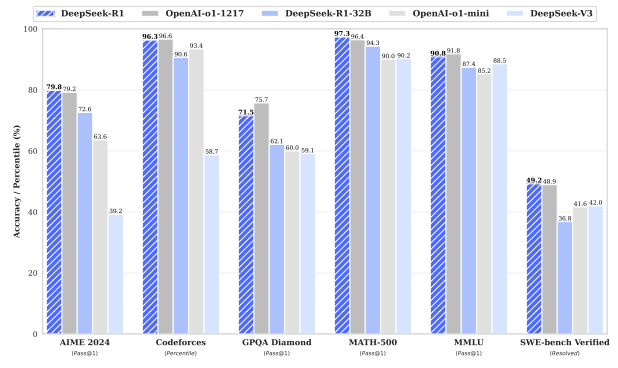
The impact was swift and immediate.
DeepSeek’s app soared to #1 on both Apple’s App Store and Android’s Google Play store.
On the other side, the US stock market history suffered its largest single-day loss ever. Highlighting the growing importance of AI to the global economy and national security.
However, this time, the market got it wrong.
Seeking Deeper Answers
DeepSeek’s most notable innovations are a lower development cost and a reinforced learning LLM training model.
The first claim is the most controversial.
Officially, DeepSeek publicly claimed that its R1 LLM cost only $6 million to train.
This may be true, but it likely spent more than $500 million on hardware and development according to those with knowledge of the firm.
Not only does it have the financial resources to pull this off, given that it spun out of a $13 billion hedge fund. But this would also be closer in-line with peers such as OpenAI, which spent more than $100 million to develop GPT-4.
The second part of the equation – DeepSeek’s foundational large-scale reinforcement learning (RL) model, is what is more impressive.
By turning a small, non-reasoning model into a reasoning one via fine tuning, DeepSeek has pushed the boundaries of efficiency.
However, it was always a matter of when smaller, newer models would achieve comparable outputs to larger, older models, and not if this would happen.
This is inference cost collapsing in real-time, similar to how computers have gotten smaller, but more powerful over time.
The CEO of Anthropic, Dario Amodei, estimates that going forward, with each passing year, it will take 10x less computing power to achieve the same results. Double the current 5x figure.
So, DeepSeek was an inevitability rather than an outlier.
The multi-trillion-dollar question now is, what comes next?
Jevons Paradox Strikes Again!
This was the first sentence of Microsoft CEO Satya Nadella’s recent X post.
At its core, the Jevons Paradox, named after a 19th-century assayer turned economist, is when increased efficiency in production drives increased demand.
In the same post Nadella stated “As AI gets more efficient and accessible, we will see its use skyrocket, turning it into a commodity we just can’t get enough of.”
At Cadenza we have experienced this firsthand.
Portfolio company Together.ai, which has one of the fastest and lowest-cost cloud AI platforms, has been adding users and aggressively growing revenue over the past year.

Another portfolio company, Jericho Security, which we have previously written about and who created cyberGPT for enterprise cybersecurity. It is a prime example of domain-specific intelligence arising from easier access to LLMs.

As we can see, DeepSeek’s launch benefits developers and early-stage startups, who now have more affordable access to cutting-edge AI tools to build with.
Large enterprises also profit by having more choice for less cost.
All of this means increased demand, as William Stanley Jevons predicted more than a century ago.
Two things come next as the AI landscape evolves.
The first is a temporary dip in Graphics Processing Unit (GPU) demand for training LLMs.
However, this will quickly be made up by the broader need for GPUs beyond just large model training. Software development, advanced data processing, autonomous driving, and cryptocurrency mining, all require GPUs to varying degrees and such use cases are now proliferating.
The second is a move up on the AI scaling curve towards AGI.
Since we are a little more than halfway to this lofty aim by most estimates, it will take longer to realize. But it will be worth the wait.
Not only will this require billions of dollars worth of GPUs to realize, but the number of new use cases and innovations that will come from AI automating AI research itself is almost unfathomable.
From this perspective, what comes next is unknowable.
If you found this insightful, you will also like The Digital Asset Golden Age: Why Digital Assets Will Skyrocket Under A Trump Presidency and The Tokenization of Real World Assets – Bigger Than The Internet?
If you would like more information on our thesis surrounding The Future of AI or other transformative technologies, please email info@cadenza.vc
