

The entire world wants more artificial intelligence (AI).
However, more AI requires production-ready Large Language Models (LLMs), which take time and money to develop.
One platform custom-made for AI developers is aiming to help with this and reduce the ramp time for new LLMs. In this post, we will unpack what it is an how it is changing the game.
A Three-Layered LLM Cake
Large Language Models are the engine that powers AI.
Much like an engine that makes a thing run, there are several parts or in the case of LLMs, layers, that it is composed of.
If we look under the hood at LLM architecture, what we will find, besides LARGE amounts of data, are three layers.
LLMs are typically comprised of:
- An input layer
- Hidden layers
- An output layer
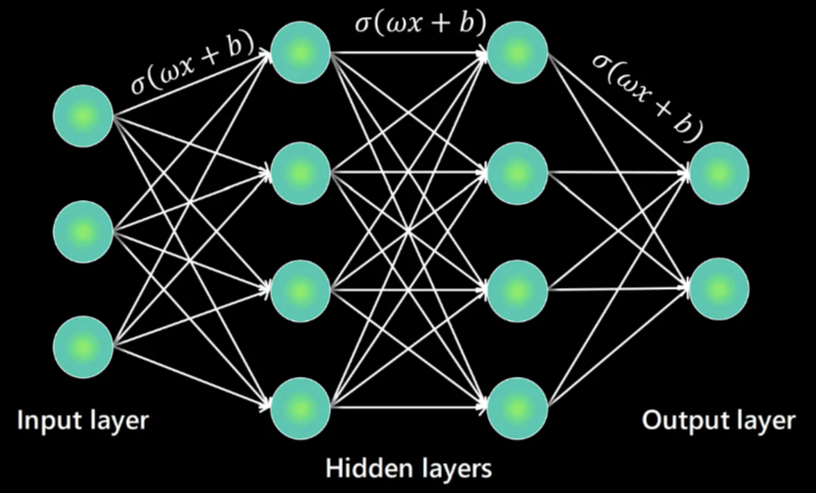
These are neural network layers that work in unison to process our text prompts and generate relevant outputs.
Without getting too technical, the input layer takes data and makes it legible for the neural network. The hidden layers in the middle process this data, and the output layer finishes the job by responding to queries with relevant data.
This might sound easy, but things can get complex quickly depending on an LLMs size and parameters.
As an example, Elon Musk’s artificial intelligence startup, xAI, has developed the largest open-source LLM to date. Grok-2 boasts an astounding 314 billion parameters.
To accomplish this, it took 15,000 Nvidia Graphics Processing Units (GPUs), Grok engineers training the model from scratch, and millions of dollars.
The company’s next-generation Grok 3 model is even more ambitious.
After raising a huge $6 billion Series C funding round late last year, xAI is now stockpiling 100,000 Nvidia H100 GPUs to train its latest model.
With each 80 Gigabyte H100 costing $30,000-$40,000, its an expensive undertaking.
Given the level of upfront investment, testing, optimizing, and getting an LLM to the production stage is top priority.
The Golden Dataset
One of the first steps of evaluating an LLM is establishing the quality of its data.
To date, a ‘Golden Dataset’ has been the benchmark.
This is made up of high-quality, curated data or “true data” that is used as a reference standard for the entire model.
The steps in creating a Golden Dataset are numerous and include data collection, labeling, and maintenance, among others.
As you can expect, this process can get time-consuming and costly for running large models. Two things that run contradictory to the speed and efficiency necessary in AI applications.
But until recently, Golden Datasets were one of the only ways to make sure applications performed optimally in controlled environments.
Now there’s a better way.
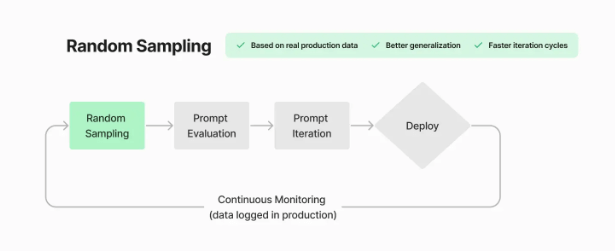
Instead of a resource-intensive operation, random sampling of data has emerged as a faster, more agile solution.
Through classic trial and error, researchers have found that randomly selecting a small subset of user interactions is a better benchmark for several reasons.
First, sampling a subset of production data is more cost-effective than evaluating an entire pre-production dataset.
Second, data that is representative of actual user interactions is far more valuable than curated data.
The question now is, can random sampling be easily implemented and what else is key to optimizing LLM performance?
Unlocking LLMs’ Full Potential
Taking a large-scale LLM from MVP to production is expensive, time-consuming, and tedious.
But it doesn’t have to be.
Helicone was founded in 2022 as an open-source LLM observability platform with a simple and straightforward goal: to make it easier for developers to monitor, manage, and optimize their AI applications at scale.

This requires some built-in features that are improvements over the current status-quo.
The first thing that stands out about the platform is being able to manage all LLM-powered workflows from one clean, easy-to-use dashboard.
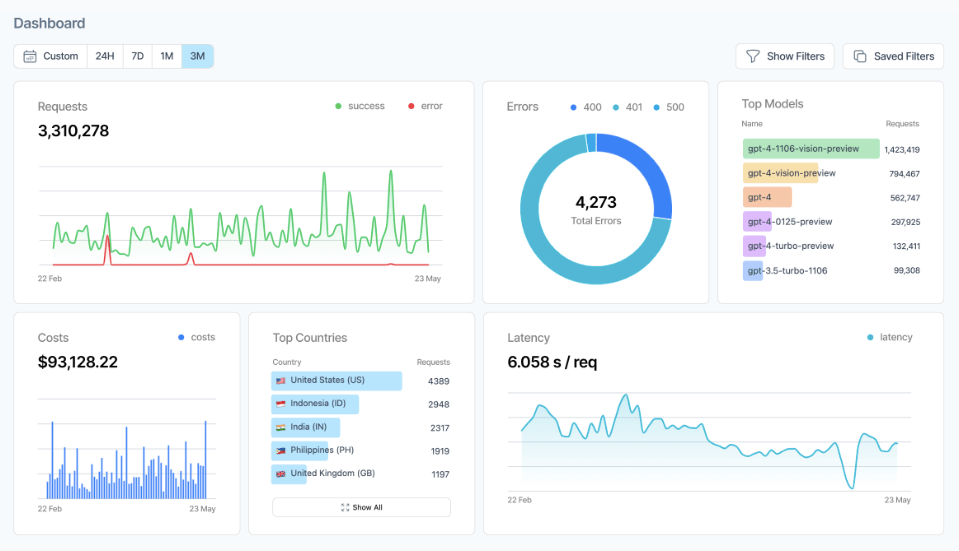
From logging and tracking all LLM production data to continuous monitoring of datasets, Helicone does it all.
Helicone’s platform also helps developers overcome the great ‘Golden Dataset’ challenge we highlighted earlier through random data sampling.
As an example, the recent QA Wolf partnership helped the native AI testing service randomly sample production data, use it to iterate on prompt definitions, and evaluate the impact of those changes against real-world benchmarks.
But the platform goes beyond just logging and tracking. It also supports LLM performance optimization in every way.
This starts with code-less prompt experimentation, which tests, evaluates, and improves prompts in real-time while also preventing regressions in production-ready LLMs.
It continues with something that is critical for long-term LLM quality: fine-tuning.
This is a topic we have covered here in the past and Helicone isn’t the only platform in town, so what sets it apart?
Well, Helicone has actually come out and documented the limitations of fine-tuning.
While highlighting the power of base models as being faster, cheaper, and more powerful, some alternatives to fine-tuning were also provided.
Foremost among these is building a Retrieval-Augmented Generation (RAG) chatbot. By using Helicone to do this, you would be combining the power of external knowledge retrieval, while allowing your LLM to access and utilize specialized information without fine-tuning.
But even more than all the features, Helicone is simply a quality platform.
As per a growing collection of real customer reviews, it just works and the support is second to none. A rarity in today’s do-it-yourself culture.
The platform’s stats back this up, with 2.1 billion requests handled and more than 18 million users.
There has never been a more opportune time to build and launch an AI application.
As recent events have shown, generative AI infrastructure providers are becoming increasingly commoditized.
At the same time, applications built on top of this infrastructure that automate tasks, innovate new products and services, and otherwise make our lives easier, are becoming more valuable.
Just like how websites such as Amazon and eBay ultimately went on to become more valuable than web hosts like GoDaddy during the dot com boom.
Something similar is beginning to play out now, although it will take time for the market to realize and price this in.
Platforms like Helicone are an essential supplier and partner for the next generation of AI applications being built, that will go on to create more wealth than anything we have previously witnessed.
If you found this insightful, you will also like Raising the Bar: How AI is Transforming the Legal Practice and Charting New Territory: How DePIN is Changing The Physical World With Digital Technology
If you would like more information on our thesis surrounding AI or other transformative technologies, please email info@cadenza.vc
